Experiments in Search
Starting out ..
I approached this exercise knowing a little about NLP. In data science roles I'd previously worked on some related topics, using neural networks to classify expenses that could then be assigned to accounting codes at Xero for example. While I was not an expert, I knew that search problems are essentially data modelling problems. The latest advancements in NLP make classification much simpler than it has been previously.
Instead of utilising manually intensive techniques processing like term frequency counts, fuzzy matching, tokenisation, lemmatization, stemming and all of the usual approaches, you can automatically split unstructured texts into whatever character lengths you prefer, and easily create mathematical representation of those splits by utilising pre-trained large language models, with some fine tuning added as necessary. The mathematical representations of the texts (aka vector embeddings) are only as good as the model applied, so when the models get good, so do the results. And the models are very good now indeed.
You then can pop those mathematical representation of the texts into a database, mapped (or indexed) against the document id, coupled with relevant metadata such as created dates, last accessed dates, authors, who else has accessed it - whatever information that you want to append to help refine and optimise the retrieval functionality.
The database we use is purposefully built to optimise performance over this kind of data - to store, manage, and associate those representations. When you want to find texts that are related, you can generate a query - that query is also transformed into a mathematical representation - then your search engine finds the closest mathematical matches between search and result. Your engine then produces a set of results that most closely match the search query.
Once you've got the output, you can apply rules around how, when, and what will be shown to the user, combining methods from keyword search to speed up retrieval time also. This is referred to as hybrid search... And so with that general process + optimisation we can develop a baseline advanced search application. Something that would have been very complex even just 5 years ago can now be built with relative ease.
Ask and you shall retrieve...
To start with, I read about search, following some courses I found online. Then I followed up with some NLP theory. That was all good and well, but I learn better if I can create something instead of just reading about it.
Online for some time I'd seen content about a framework called Langchain. I knew about some vector database products that already existed such as Pinecone, Vectara, Weaviate, Milvius, Elastic + Qdrant (I'm sure there are more now). So I chose to try out Pinecone with Langchain. This was because it offered a free tier, and had a well documented library. I'd used Weaviate a bit before that - but found it to be overwhelmingly complicated. So Pinecone was the best option and I signed up for the waitlist.
For the start up programme I had generated around 30 documents that were intended to use as a proxy for testing and learning. They included a mix of documents like analysis write ups, experiment plans, PRDs, Post-mortems, RFCs, and chats between different team members. The intention was that they would be used as a representation of the types of documents that a technology team would use in their work. I loaded those documents into a GCP storage bucket and fired up VS code.
The initial steps involved were to:
First import documents from cloud storage and then break the documents down into smaller chunks. Here you could determine character length and text overlap. In my case I broke the documents into 400 character lengths, with a 100 character overlap.

After splitting the documents out, the next step was to create embeddings of the text chunks. For this I used open AI embeddings endpoint, but you can choose from practically any LLM that offers an embeddings API service.
After this I created what is called an Index using Pinecone - essentially a data store where you can define how many dimensions to include for each item. These items impact performance and storage - you can read more on that here.
You can also choose whether to calculate the similarity of items based on a cosine or a euclidian distance metric. I had learned that the best option in most cases is to go with a cosine similarity score as it accounts for different weightings and biases in the training dataset.
After this I connected Langchain with Pinecone and imported the data from the split documents into the index. This took a reasonable amount of time. Possibly in part because I included a csv that was quite large, it was a random jumble of document titles and metadata that I'd generated for the purpose of generating a cluster analysis (will write an article on this later).
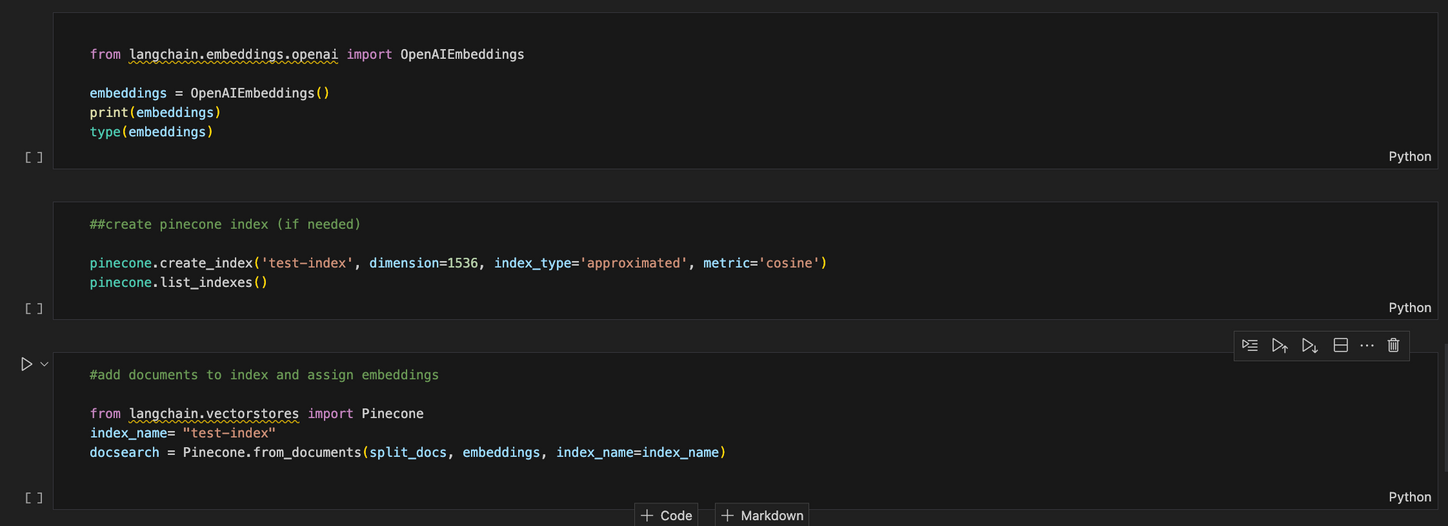
After this, I imported Langchain retrieval packages, one would return a generated text answer, and the other would also generate an answer to the query but would also return the source metadata (eg: document title) .
Some of the options here include what is called a temperature parameter. This refers to the creativity level of the response. A higher temperature variable will return a more random and creatively tuned response.
Here the script took about 7 seconds to return a quite long-winded answer.
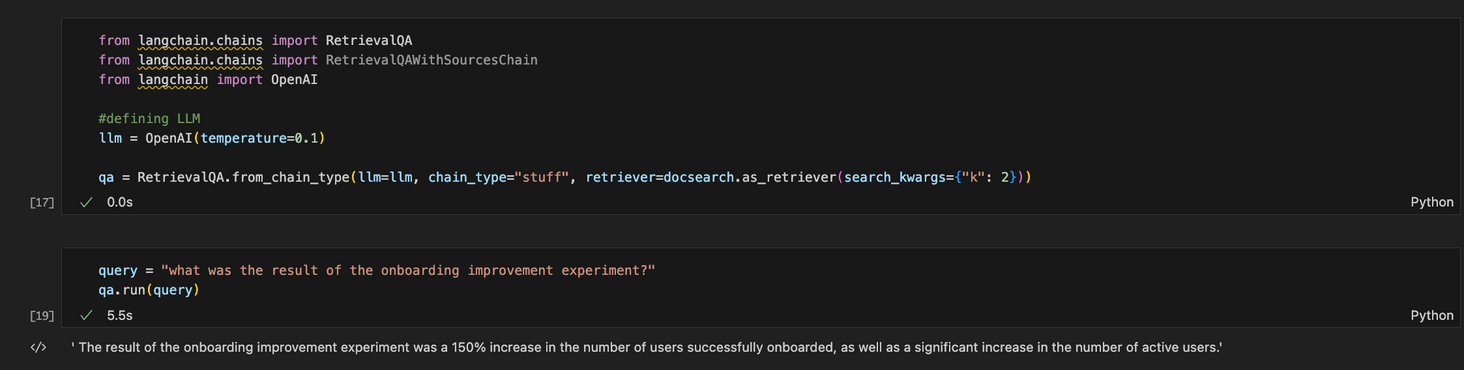
This took me about half a day of reading and configuration to set up. While far from perfect, it demonstrates how with modern tool and frameworks it can be relatively easy to set up a simple question and answer service over specific texts.
Of course, avoiding misinformation is important. I ran a specific query that I knew there was no document about "why did sales of kayaks spike in December?" - and it came back with 'I don't know' which was better than making things up.
However when I asked about something vague yet plausible - "What happened last December with payments?" it indeed generated a hallucinated response that was written as fact: "Many people had a higher disposable income to spend during December due to holiday gifts.' Ideally, the retrieval mechanism would ask for more information before generating a response... I'm sure this will eventuate as things evolve.
So there's some work to do with Q + A and generated responses, for now best avoided until answers can be determined as reliable.
Summary
It that much easier to build a usable search engine - where are the best product and business opportunities? I believe that long term value exists in the space between different applications. And accordingly, at the product level.
There are quite a few search type of products coming out now with many applications for different users - they are like google for work documents.
By mapping the target user's complete workflow, and optimising usage and application for them and their work - I believe that is how to really find the right spot to solve good problems.